Applying V to study achievement gaps
Contents
In the last post I talked about one method to estimate distributional differences from ordinal data, such as those reported by statewide accountability systems. In this post, we’ll put this method to work for the state of California. I’ll show how we can estimate school-level Hispanic/White achievement gaps for every school in the state that reports data on both groups. In California, this means the school must have at least 30 students in each group, for the corresponding grade.
The data
The primary data we’ll be looking at are available here. As I mentioned in the previous post, part of what I think is so cool about this method is that these data are reported across all states, so you could apply this method with any state. I chose California here because I have some experience with their specific data, I’m a west-coaster, and California is more interesting than Oregon (where I live) because they are much more diverse and have areas of dense population.
These data have a number of numeric codes in them that don’t make much sense without the code book, which is available here.
I’m also always interested in geographic variance in social things, including school performance, so I also like to try to grab the longitude and latitude of the schools. That’s available through a separate file, available here. Note that geographic information is available more generally for every public school in the country through the National Center for Education Statistics (NCES) Education Demographic and Geographic Estimates (EDGE) program.
Loading the data
We could, of course, just visit these websites and pull the data down and load it in manually, but that’s no fun. This is R. Let’s do it through code!
The file we want is at http://www3.cde.ca.gov/caasppresearchfiles/2018/sb/sb_ca2018_all_csv_v3.zip. The tricky part is, it’s in a zip file with one other file. One way to handle this is by creating a temporary directory, downloading the zip file there, then unzipping the file and pulling just the data we want out. In our case, the filename is the same as the zip file, but with a .txt extension. I’ll be using the tidyverse later anyway so I’ll do something like this
| |
| |
That gives us the basic file we want, but we don’t know what any of the subgroup IDs represent. To get that, we’ll have to download another datafile. This is another zip file, but note I’m using a slightly different approach below, which I can do because the zip file only contains a single file.
| |
| |
Now we can join these data
| |
| |
Preparing the data
It’s fairly difficult to see what’s going on here so let’s limit our data to only the things we really care about here. We’ll need the district and school codes, the group variables we just added in, and all the percentage in each category.
| |
| |
As you can see here at the bottom of the page, a test id of 1 means it was English Language Arts, while 2 means Mathematics.
| |
Now we’ll limit the data to only Hispanic/White students, which is the achievement gap we’ll investigate across schools. I don’t know the specific labels, so I’ll look at these first, then filter accordingly.
| |
| |
| |
| |
Notice that the school_code and district_code are both 0 here. This is the code for the overall state, which we probably want to eliminate.
| |
| |
Estimated effect sizes
We now have a pretty basic dataset that we’re ready to use to estimate effect size. If you recall from the previous post, what we need is the cumulate percentage of students in each category, rather than the raw percents. I’m going to do this by first creating a lower category that has zero students in it. I’ll then reshape the data to a long(er) format and calculate the cumulative sum.
Data prep
First, create the lower category
| |
| |
We need this because of the cumulative sum calculation that comes next. First though, let’s reshape the data. After the reshape, I do a tiny bit of cleanup so the category variable doesn’t repeat "percentage_standard_" over and over.
| |
| |
Now we need to make sure the categories are ordered in ascending order within a school. The best way to do this, from my perspective, is to transform category into a categorical variable.
| |
| |
| |
| |
And now we can calculate the cumulative percentage
| |
| |
And now we’re getting close. We just need a column for each each group. We’ll drop the raw percentage (so rows are uniquely defined) and spread the cumulative sum into to columns according to the specific group
| |
| |
This looks basically correct, but to make it a bit more clear, let’s remove schools that did not report percentages for both groups
| |
| |
And now we’re very close, but if you look carefully you can see we have one issue remaining - every school has the low category reported for both groups. We need to remove schools that only have the low category reported (because they don’t actually have any real data reported). There’s lots of ways to do this, of course, but a fairly straightforward way is to count the rows within each school/grade/test combination and make sure there are five observations (four categories, plus the low category). Then we’ll select for just those observations.
| |
| |
And our data are finally finalized! 🥳
Produce estimates
First, let’s compute the area under the paired curves. To do this, we just use an x/y integration. This will give us one estimate for each school/test/grade combination. I’ll use the {pracma} package again. One small caveat here… to get the correct AUC, the cumulative percentages actually need to be cumulative proportions. We could have done this transformation above in our data prep (and maybe I should have done that) but you can also do it in the integration and it doesn’t change the results at all. We’ll take this approach.
| |
| |
As a reminder, these values represent the probability that a randomly selected student from the x axis group, in this case students coded Hispanic/Latino, would score above a randomly selected student from the y axis group, in this case students coded White.
Now, we can transform these values into effect sizes using sqrt(2)*qnorm(auc), where auc represents the values we just calculated.
| |
| |
And voilà! We have effect size estimates for every school in California that reported data on both groups.
Quick exploration
This is already a long post, so I’ll keep this brief, but let’s quickly explore the effect size estimates.
First, let’s just look at the distributions by content area.
| |
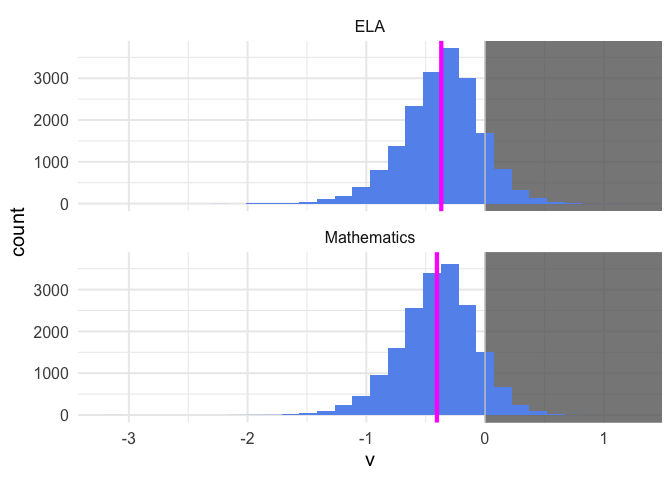
This gives us a quick understanding of the overall distribution. For the vast majority of schools, students coded Hispanic/Latino are scoring, on average, lower than students coded White. But this is not true for all schools. We can also see that these achievement disparities are, on average, slightly larger in Math than in ELA.
Notice, however, that there is considerable variability between schools. What drives this variability? This is currently my primary area of interest.
One more quick exploration, let’s look at the distributions by grade. I’ll use the {ggridges} package to produce distributions by grade.
| |
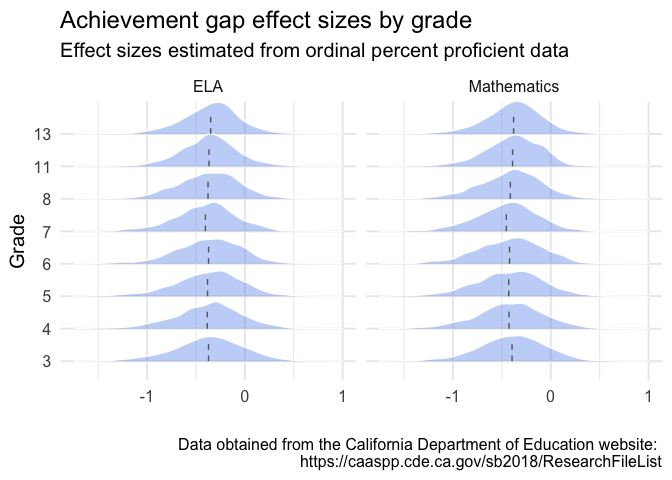
Is there evidence of the achievement gaps growing by grade? Maybe… let’s take a different look.
| |
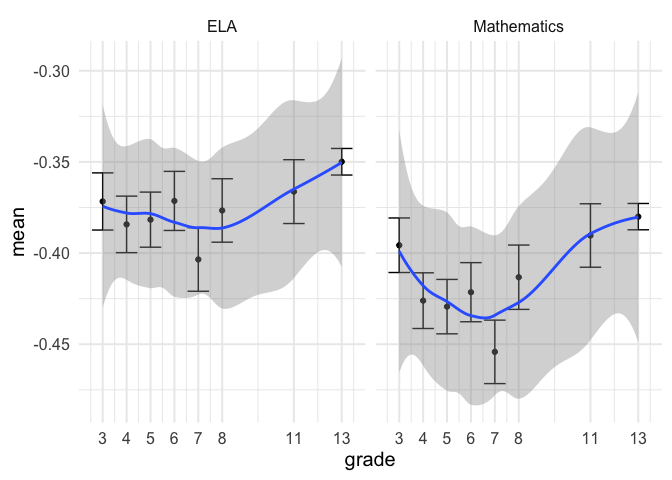
Maybe some, but the evidence is not overwhelmingly strong in this case
Conclusions
This was a long post, but an important one, I think. In the next post, I’ll talk about geographical variation in school-level achievement gaps, which will require linking the schools with data including longitude and latitude, and exploring things like census variables to explore how they may relate to the between-school variability.
Thanks for reading! Please get in touch if you found it interesting, see areas that need correcting, or have follow-up questions.
Author Daniel Anderson
LastMod 2019-08-12 (4d3acce)